 Unlimited Dream Co.
Unlimited Dream Co.Every AI artist will has their own prompt-writing style, but in this series of articles I’ll explain the techniques that I've developed that work well for me. Hopefully this will help you understand how prompts work and give you pointers to developing your own style.
For the purposes of this article, I’m going to assume you’re familiar with using VQGAN+CLIP on Google Colab. If you’re just starting out, I’d recommend reading my article on getting started before going further. I’m also using Pytti 5 as it’s my preferred notebook, but the concepts I’ll be talking about will work with any VQGAN+CLIP notebook.
What are prompts and how do they work?
The prompt is how you tell the CLIP and VQGAN neural networks what you want them to do. Imagine that inside them there’s a drunk genie who takes your instructions and carries them out in unexpected ways. Sometimes the results are amazing, other times not. Getting good results involves understanding a bit about how the system works.
Put simply, CLIP is a discriminator neural network. Give it some text, for example ‘a stone temple’, and it’ll be able to identify images of stone temples, as well as of stones and temples in general. It works backwards too – give it a picture of a stone temple and it’ll return the words ‘stone temple’. To achieve this, it was trained on millions of images and their related text descriptions, so it’s able make the link between pretty much any set of words and the objects or concepts they describe.
VQGAN is a generator network that’s able to create images that look like other images, using a dataset which itself has been trained on millions of images. So, for example, if CLIP asks it for ‘a stone temple’, it’ll use the dataset to create a picture of a stone temple. At first the generated image won’t look much like the prompt, but over many iterations the two networks go back and forth until the image looks almost, but not quite entirely unlike a stone temple.

↑ ‘A stone temple', 20, 200 and 600 iterations.
The end result is a mix of what CLIP sees when it reads your prompt and what’s in the dataset that VQGAN uses to create the image. If your prompt contains something CLIP doesn’t know about or is not in the dataset then it can lead to unexpected (and sometimes interesting) results. CLIP may also misunderstand your intention, interpret your words in multiple ways, or include other things in the image that you didn't want.
The challenge therefore is to construct your prompt in a way that works with CLIP and VQGAN’s understanding of the world and gives you as much control over the output as possible, maximising the effects you want and minimising those you don’t. This is known informally as ‘prompt engineering’ and is totally going to be someone’s job title soon. Hopefully mine.
Basic prompts
It’s fine to use very simple prompts, for example 'A stone temple' , but if you do, you’re not going to get particularly interesting results. It’s the equivalent of leaving all the settings on default. To get the best out of it, you’re going to need to work a bit harder.

↑ ‘A stone temple’, 1000 iterations.
Style modifiers
Not long after VQGAN+CLIP came out, people found that it didn’t just know about the subject of an image, but also the website where the training images were taken from, the type of image (painting, drawing, photo etc.), and even the film stock or rendering engine used to create it – and much more besides.
This allows for vastly more creative control over the image and suddenly writing the prompt becomes not just about what the image should be, but how it looks as well.
Examples
Here are a few examples of the difference style modifiers can make to the image. I've used the same seed throughout, so the only thing that's different between them is the prompt.
Trending on Artstation

↑ ‘A stone temple | Trending on Artstation’, 1000 iterations.
This was an early discovery. Artstation is a site where digital artists share their work and leans heavily towards sci-fi and concept art. Adding the 'Trending on Artstation' style modifier produces a distinctive painterly look with lots of cyan, red and purple. It probably shouldn’t be used without further modifiers as it’s almost become a cliché, but I do use it in my prompts as a sort of sweetener as I like the vivid colours it produces.
It also seems to have added in some monks, I guess because monks are often found in temples, but it's a good example of the system adding elements we didn't specifically ask for.
Unreal Engine
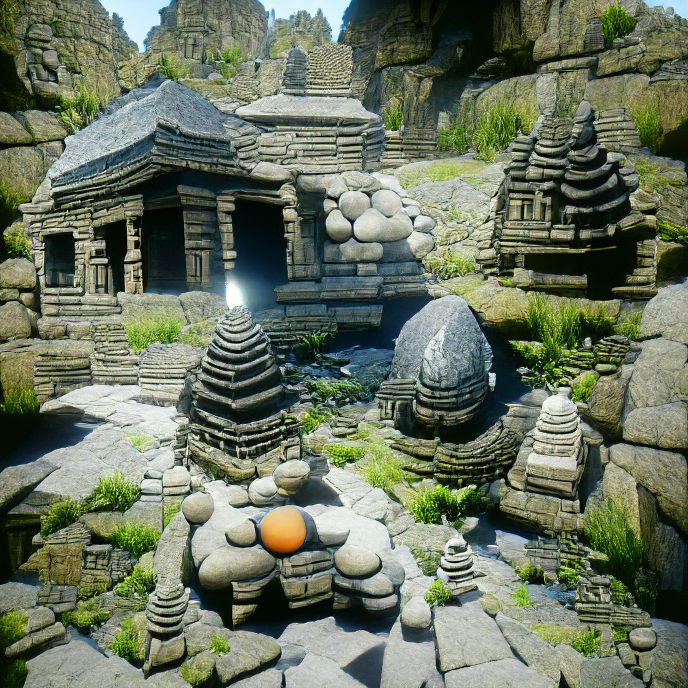
↑ ‘A stone temple | Unreal Engine’, 1000 iterations.
As you can see, adding ‘Unreal Engine’ to the prompt generates a more realistic, wide-angled 3D image. Even though it wasn’t actually rendered with Unreal Engine, it looks pretty close.
Creating your own modifiers
Here's some pointers for creating your own style modifiers:
Media – What materials were used to 'create' your image? Is it a photo, a watercolour painting or a sculpture? If it was a photo, what film stock was used? What happens when you add them to the prompt?
Training dataset – Where were the images the dataset was trained on taken from? We've seen the effect Artstation has, but does Flickr, Dribbble or 500px make a difference too?
Renderer and resolution – We know that adding Unreal Engine makes for a more realistic image, but does it also work for other rendering engines? What if we just tell it to create a more detailed image – for example 'Ultra high definition 8K wallpaper' – would that have an effect?

↑ Top left: ‘A charcoal drawing of a stone temple', Top right: 'An ultra-high definition 8K wallpaper of a stone temple', Bottom left: 'A 500px HDR photograph of a stone temple', Bottom right: 'A stone temple | subsurface scattering',
Examples
Some heroic people have spent a lot of time developing and cataloguing style modifiers – this gallery by @kingdomakrillic is a good place to start.

↑ A small sample of the full list. Thanks to @kingdomakrillic for all their hard work.
The best thing to do is experiment, try things and find out what works. Not everything will be successful, but when it is, it’s likely to produce something amazing, or at least interesting. There’s no limit to what you can do and you never know what might happen.
Next: Artist and genre modifiers.
Thanks for reading! If you have any questions, comments or suggestions, I’d love to hear from you. Give me a shout on Twitter, or send an email.