 Unlimited Dream Co.
Unlimited Dream Co.What’s your background and what do you do when you’re not making AI art?
VJ_DMTFL: I came from the world of musical archival and digital netlabels. My life up until last year was nearly-exclusively based on audio engineering, sound and music distribution. Since I was a teenager I've been an avid digital record collector and I spent most of the years leading up to AI art as a labelrunner for a vaporwave collective. When I'm not making AI art I am usually teaching myself about, collecting, and/or listening to new music, and when I'm not at a computer you can usually find me out at one of the local nature parks, or at church!
What are you working on right now?
VJ_DMTFL: Right now I am attempting to canonize my journey into VQGAN+CLIP, the mainstay generator I used for most of the last year and a half. I'm attempting to take every animated GIF I created as a result of AI art so that I may classify them for easy access as a creator as well as easy viewership for those who like my work.
In addition to this canonization effort, I'm exploring the various ways that Stable Diffusion can be uniquely applied in ways that the other AI image synthesis tools cannot. While I sometimes do use my images on albums or music-related content I make, there is simply too much content for me to do this every time. I'd like to figure out where to best display both the old VQGAN+CLIP canon as well as this upcoming Stable Diffusion haul I continue to be fascinated with.
How did you first get started using AI in your work and what was your ‘aha’ moment?
VJ_DMTFL: I was lucky to stumble onto the right thread in a technology forum in early 2021, shortly after my 29th birthday. I was sitting on the couch looking at people's results on my phone and I kept being skeptical that people were really making these images from text input alone. The tool being featured in this thread I found was for BigGAN+CLIP (also known colloquially as The Big Sleep, created by Advadnoun), which did not yet feature the input image nor did it have prompt weighting.
Nevertheless, the outputs that I was seeing from other users were mindblowing. So I excused myself into the other room where the computer was to try the link. Minutes later, looking at my first synthesized image, I called my wife so we could marvel at it together. From that exact point onward, she and I were obsessed. I was convinced utterly that this was the next big innovation that the rest of this decade (or maybe even this century) would be tailored towards.
What was the first piece you created?

↑ Worlds of Possibilities (2021).
VJ_DMTFL: The first piece I created was called World of Possibilities. I sadly didn't realize how important prompt-saving was so I no longer have the exact wording, but I do remember it was a mixture of words that included "vaporwave, computer, user interface, screen, vacation view".
The resulting image was unlike anything I had ever seen. It resembled a series of surveillance screens that were monitoring different regions of what looked like some kind of island getaway. The interface resembled one of those old 1990s tycoon simulators, and the bright pink background framed the totality of the scene. To this day, I have my randomizer screensaver for the computer set so that the very first image it shows is that one.
I’d love to explore the link between your visual art and your music – how have you found they relate, and what are the similarities or differences?

↑ ULTIMA 010E102 - Complete Collection of Acquired Knowledge.
VJ_DMTFL: For my background in the Vaporwave genre, I've had a lot of joy working with the concept of turning old things into new things, as the Vaporwave genre was built upon (and exists to this day to a major degree because of) the usage of old song samples in the creation of making new songs.
When I learned about how AI image compositing works, it felt like I had been working for years with something like image synthesis in mind. The way that these imagesets come together to create entirely new images from a litany of older reference material, it feels like a quantum-speed version of what I and others in the Vaporwave genre have been doing all 2010s long. I greatly enjoy this parallel, and even more I enjoy trying to create musical experiences that are themed (both in content and in atmosphere) to the images that I am able to generate.
I also am a huge fan of how immersive music can be when juxtaposed to rapid-fire animated versions of these AI images. My record label nearly-exclusively works in AI imagery as of mid-2021 due to my inability to separate the two. Perhaps the largest contrast between AI images and the music I make is that I cannot seem to generate the same feeling of awe out of personally-made music as I can get from personally-generated images. However, I feel like the audio GANs are going to catch up to the visual side of things before long.
One of the fun things about AI is its unexpectedness. Which piece are happiest with –and which surprised you the most?
VJ_DMTFL: Great question! There has been so much circumvention of expectation in watching AI images form themselves, and as of this week with starting very late at finally getting my hands on Stable Diffusion, I've found this model to be wildly variable in what it gives you.
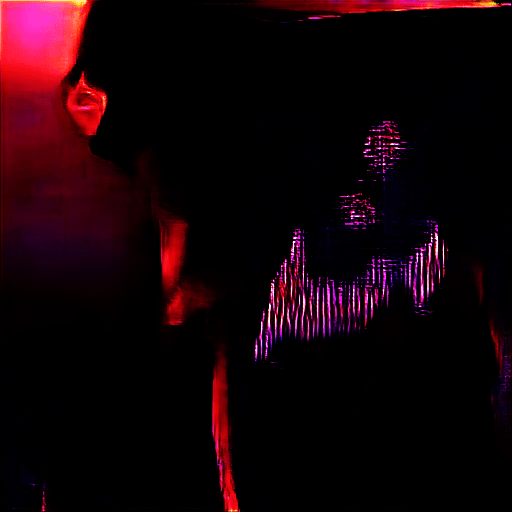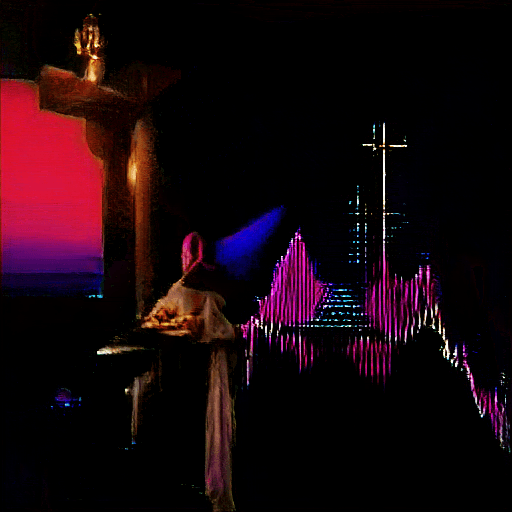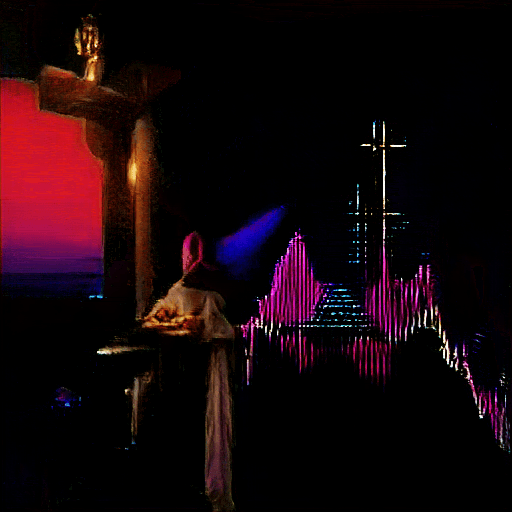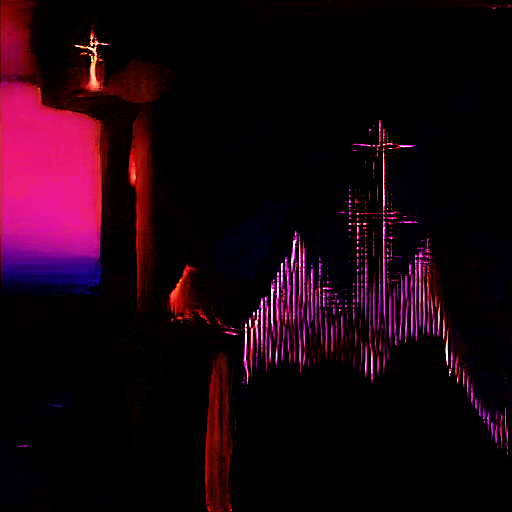
↑ A Baptism of Solitude (2021).
However, if we're talking about my all-time favorite unexpected moment from all generators combined, I have to say the best one was from an early BigGAN (aka The Big Sleep) generation where I asked for "a baptism of solitude" (based on an instrumental song of the same name by guitarist Buckethead). I thought maybe I would get people in a river out in the middle of nowhere, some silent looking place where people are getting baptized.
The resulting image that started to form in was one of the most elaborate images I've ever seen, with a monk slowly having a light from above shine onto his head as you see he is at a baptism altar, and a giant crucifix shimmering in the background to reveal a sort of first century depiction. It was so detailed without any need to specify any of what I got, and the lone monk being given a small mote of light to work by in his solitude was breathtaking. BigGAN had completely fulfilled the prompt's request on such few words. This was my most surprising output.

↑ Ultra Deco Universe Terminal (2022).
As for my very favorite output, it has to be the first time I figured out the ULTRA DECO prompt, which is a top-secret nine word combination that I have slowly been modifying and progressing into a whole multigenerational family of prompts. It was one of the first times that an image I was seeing in my head was successfully rendered nearly-identically as I was envisioning it. In this case, it was bringing heavy digital color saturation to statues that resembled the 1910s/1920s art deco boom. I wanted to do a century-later homage to these now-considered-outdated visual tropes, and my satisfaction in the first image led to ULTRA DECO becoming my largest and most signature exhibit by volume.
Your work digs deeply into art history, it’s varied but always has a distinct style – I can always tell when a piece is yours. How would you describe your style and when did you first see it develop?

↑ DOOMCATION 018E008 - Exploration of the New Coastline.
VJ_DMTFL: Thank you for saying that. It's funny because I have always tried distinguishing some of the different genres from one another as I create, but as of lately, I have merged and hybridized so many of the exhibits that I have tons of images that might resemble 2, 3, 4 different prompt families I've made.
I'd say my style started to develop after about three or four months into AI art, especially when I started using VQGAN+CLIP with its ability to introduce input and objective images.
Certain aspects of my everyday life and general history have become a central theme to my prompts. I'll tell you now that many of my prompts include words such as 'vaporwave' (my last eight years of genre obsession and my music career), 'Florida' (my lifelong home and personal natural inspiration), 'in vivid color' (or some variation thereof). That last one is what I have sought to try and make my biggest mark on AI art within: high-saturation color experimentation.

↑ VACATIONSCAPES 001E257 - Home is the Holiday.
VJ_DMTFL: While not all of my exhibits are color-focused, a good 75-80% of them are about trying to introduce shades and hues that catch the eye first, then introduce the subject matter second.
One of my major goals is to be the most colorful artist on people's AI feeds, thanks to VQGAN+CLIP's seemingly exclusive 'objective image' feature, as well as the spliced-together input image found on the Simple Stable Colab by @ai_curio.
The art history aspect of this campaign has been a blast for me. I myself didn't immerse myself into nearly as much as I know now, as the act of being a student of art now has a distinct advantage in being able to craft prompts in relation to specific movements or names or periods. I tried to do a little bit of tribute to each era of modern art (roughly 18th through 21st century) in each exhibit to help encourage replicatable images for other AI promptmakers and artists alike to enjoy.
I’d love to know a bit more about your process – please talk me through the creation of a piece, from beginning to end.
VJ_DMTFL: For my VQGAN+CLIP process, I've developed a few techniques that help me make images I want to actually save, animate, and canonize. In order to do this, I've built a series of image archives. One is an input image junk drawer folder with every and any compositionally interesting image I might think could be adapted; many come from my old digital photos from 2004 onward, old 1990s family photos, still-frames from old '80s/'90s advertisements from when I used to make collage-style music videos in my vaporwave days, classic art, and other found scraps. I also would make purposefully minimal, bare, somewhat unimpressive mockup images in Windows Paint and I would use them as overlays on other images to help direct the flow. All of this is my process of determining a good input image.

↑ MAGRITTE AI 022E039 - It's a Sickness I Know.
VQGAN+CLIP is interesting in that it also has the objective image, or target image feature. This is crucial for directing the color of your piece in that particular engine, as whatever image you put in this parameter will adapt its shades to the input image. You can, if you choose, do zero text input and just have an input and an objective image. You can also weight the objective images and have it reference several images at once to colorize. This is a tip I did not find anywhere but rather learned from using the GAN myself over time.
I still think that VQGAN+CLIP has more powerful capabilities than many other tools because of this input/target image system. In setting up good objective/target images, I normally recycle my own AI pieces that came out colorfully from text and input alone, taking the most saturated of them and putting them in their own folder.

↑ PORT RICHEY RETROFUTURISM 013E103 - Nostalgia So Beautiful.
As for the text prompts, I've slowly been building them from sentence fragments and word experiments all saved in a series of archived text files. I have them organized into their respective exhibit names which create prompt families, sometimes they all have the same suffix in common or maybe the same nine-word phrase was the root prompt and each variation changes just a single word or adds a word or two. Trying to find fidelity among the prompts where the images feel similar to one another is a major goal for me. Using the objective image to direct color and the input image to direct form, the textural subject matter of the image is finally given the text treatment. I will usually configure my input and target images and then keep them the same for dozens of text prompts, keeping things similar and subtly changing variations until the end result of iterations.

↑ NATURESCAPES 021E102 - Pillow Fort Forest.
I almost always set my iteration number to 33, and usually the animation .jpgs begin at i:99. I will take at least three of the best looking images (oftentimes sequential to one another) and then run them together into a simple GIF animator. The new GIF gets filed away into its respective exhibit folder until I come around to canonize them by numbering and titling them, and then once ready, I usually post the new pieces to announce they're new additions to the preexisting style exhibits!
(I appreciate you asking this, I don't think I've ever typed out the process before this even though I know it by heart after all this time!)
How have you found the transition from VQGAN to Stable Diffusion? What was different?

↑ Stable Diffusion Sneak Peek 1.
VJ_DMTFL: Stable Diffusion has changed the game for me, as rather than it being progressive iterations of the image that I am working with, Diffusion generates wildly different variations as if you're rapidly firing through various prompts. I will say that I am still figuring out if my future in the Stable Diffusion arena will be animation based or if I will adopt more of a still-frame approach due to how this generator (at least to my availability and aptitude) allows me to create.
Having said all of this, I am quite thrilled by the transformative capabilities found in Stable Diffusion. I didn't really do much with any of the tools that happened between VQGAN+CLIP and Stable Diffusion: I didn't use DALL-E, Disco Diffusion, Midjourney, CLIP-Guided Diffusion etc. I liked the results I saw from others but I didn't want to spread myself too thin because, personally, it takes me a long time to gain understanding and aptitude towards what I'm doing.

↑ Stable Diffusion Sneak Peek 15.
Having one interface to learn in VQGAN+CLIP and trying to perfect my vision of what I can make with it became more of an exciting challenge to me than going and demoing every new generator that arrived. But there's nothing wrong with those who took that multidisciplinary approach to learning new models as soon as they're available. Good on the people who can make that work for them, because I have always wanted to have that flexibility.
It feels finally time to adapt to this second major image synthesis tool as I have so many things I can now do in it that were not even possible in VQGAN+CLIP.
What’s next for you and what are you hoping for?
VJ_DMTFL: I'm figuring out how I want to best present and apply my Stable Diffusion outputs, as well as taking all the text prompts I made for BigGAN and VQGAN+CLIP (possibly over a thousand) and seeing which ones will work, versus which ones might have to be VQ-exclusive.

↑ Stable Diffusion Sneak Peek 8.
I am also planning on heavily emphasizing and campaigning into all art spaces (both AI and non) a spirit of open-sample, free use of all of my images made with AI, whether it be direct use without any change or creative transformation of their own works. I have been recommending all VQGAN+CLIP users to use my images as their objective image, and now I am encouraging all Stable Diffusion users to use my images as their input images. I want to promote a spirit of collaboration within the AI art paradigm and this is the best way I think I can do it!
Who should I speak to next and why?
VJ_DMTFL: @singlezer0 is one of my big influences on the animation side of things; he would do frame-by-frame animation recreations of his own face and the result was, both at the time over a year ago and still to this day, one of the most exciting applications of AI I have seen yet.
At that time, many people (myself included) were just animating together the different iterations of output, but @singlezer0 would take original video, separate all the frames, synthesize each one equally, and then put them back together. It is a practice I now see more and more AI artists committing to, but @singlezer0 was the very first that I saw do this on a major scale and still remains one of the most impressive at the game today.

↑ Stable Diffusion Sneak Peek 13.
@images_ai, who I have a feeling you maybe already spoke to (I certainly have – Ed.) is one of the most important popularisers of AI image synthesis, being featured in The New Yorker and various other major publications for their incredible work using VQGAN+CLIP. They were the first major Twitter account to showcase AI art and provide information about how to create your own – and were the first AI art account to 'go viral'.
They created the most famous VQGAN+CLIP tutorial – it was so popular that sometimes the link was not easy to access (Google would have a little pop-up to tell you when the document was experiencing higher traffic than usual, which is something I had no idea existed in Google Docs). A huge catalyst to the flourishing of AI.
Please do explore DMT Tapes FL on Bandcamp and follow VJ_DMTFL on Twitter.
Thanks for reading! If you have any questions, comments or suggestions, I’d love to hear from you. Give me a shout on Twitter, or send an email.